As with most of my mornings, they start with a coffee and reading the news on time.mk – news portals' aggregator.
At the time of writing this post, there are about 115 sources on the sources list on time.mk. As readers, we are mostly interested in unique content. Out of those 115 sources, a lot of them will generate noise. It may look something like this:

Even if you don’t understand Cyrillic, you can tell it’s definitely the same text.
So, how do we find the most unique sources and only stick to them, instead of wasting our time on copy-paste news portals that do not produce original content?
We start with the most obvious definition:
Definition 1: There exists portals 
We will just use the word portal for news portal. Every portal has a list of contents:
Definition 2: A portal 

We have a way to compute the similarity between two contents:
Definition 3: There exists a function 


So for example, given the portals on that screenshot above 




But what does this tell us about 


Definition 4: A portal 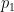
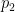

– i.e. the difference is above some threshold
that defines similarity bounds
– first article is at timestamp
– second article is at timestamp
A portal being similar just at a single point in time does not tell much. For example, maybe there was some important news where one portal was the source and others just used it as a reference to spread the news. We will accept cases like these to be okay. However, if this happens more often, then something tells us about the overall similarity between two portals.
Definition 5: For a given timestamp range 

– i.e. at least
timestamps are within the range, for some threshold
- Definition 4 applies for all timestamps
Now we have a way to represent the non-original content producing portals in a given year, say, 2018. We will have to monitor this weekly (or even daily) to see how a portal changes its trend. Given all of this information, we can construct graphs to cluster similar news sites.
The only remaining thing is for someone to build this system and save people a lot of time reading garbage. 🙂
