In this post we’ll tackle the following puzzle:
We are given two arrays, one with adjectives 


Consider the list of adjectives 


Considering the page size to be 2, we have the following options:
Page #0: A 1, A 2
Page #1: A 3, B 1
Page #2: B 2, B 3Considering the page size to be 3, we have the following options:
Page #0: A 1, A 2, A 3
Page #1: B 1, B 2, B 3The question is, is there a way to produce a programmatic and performant solution for this?
Take 1: Solution in PHP
We can directly translate the mathematical description into code and see where that leads us.
We implement the functions generateCombinations and getPage as follows:
<?php
function generateCombinations( $adjs, $nouns ) {
$list = array();
foreach ( $adjs as $adj ) {
foreach ( $nouns as $noun ) {
$list[] = $adj . ' ' . $noun;
}
}
return $list;
}
function getPage( $combinations, $pageIndex, $pageSize ) {
return array_slice( $combinations, $pageIndex * $pageSize, $pageSize );
}
So, for example, the following code produces the output:
$combinations = generateCombinations( array( 'A', 'B' ), array( '1', '2', '3' ) );
var_dump( getPage( $combinations, 0, 2 ) );
var_dump( getPage( $combinations, 1, 2 ) );
var_dump( getPage( $combinations, 2, 2 ) );
// A 1, A 2
// A 3, B 1
// B 2, B 3
Things look good so far. However, note that generateCombinations takes 
Take 2: Solution in Haskell
Well, for one thing, this problem is very easy to solve in a language that has support for lazy evaluation, because we want to avoid generating all possible combinations, and generate only those that we need – that will be used in the pagination.
Consider the following (two lines of) code in Haskell:
generateCombinations :: [String] -> [String] -> [String]
generateCombinations adjs nouns = [ adj ++ " " ++ noun | adj <- adjs, noun <- nouns ]
getPage :: [String] -> Int -> Int -> [String]
getPage combinations pageIndex pageSize = take pageSize $ drop (pageIndex * pageSize) combinations
Haskell will perform this blazingly fast, even when both of the lists of adjectives and nouns are of size 10k (which sum to 100 million combinations)..
But how can we make this faster in PHP?
Take 3: Solution in PHP
We want to get around generateCombinations somehow. One way to do it is to calculate the exact page indices we want to use and only extract those, instead of generating all combinations and going through those. Calculating page indices and sizes of a single-dimensional array is quite simple; in PHP, this is basically getPage that we saw earlier. But, in the case of two-dimensional arrays, it’s a bit trickier.
So, we want to calculate exactly which indices/offsets we need to pick from $adjs and $nouns (depending on page index and page size), and only calculate the values for those. This is possible to achieve, because the calculation $list[] = $adj . ' ' . $noun; does not depend on any previous state. So, essentially we’re doing lazy evaluation by hand in PHP, whereas in Haskell it’s done automatically for us.
So how do we approach this? Let’s consider an example, and we’ll build from there. Consider, as before, the list of adjectives
Page size 2: 

So the starting adjective indices are 0, 0, and 1 respectively for page index 0, 1, 2. Similarly, the noun indices are 0, 2, 1 respectively.
Page size 3: 

For simplicity, consider the page size to be equal to 

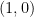

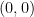


Similarly, we can determine 
Here’s the complete code:
function getPage_2( $adjs, $nouns, $pageIndex, $pageSize ) {
$adjsLen = count( $adjs );
$nounsLen = count( $nouns );
$adjIndex = floor( $pageIndex * $pageSize / $nounsLen );
$nounIndex = $pageIndex * $pageSize - $adjIndex * $nounsLen;
$list = array();
for ( $cnt = 0; $cnt < $pageSize; $cnt++, $nounIndex++ ) {
if ( $nounIndex == $nounsLen ) {
$nounIndex = 0;
$adjIndex++;
}
if ( ! isset( $adjs[ $adjIndex ] ) ) {
break;
}
$list[] = $adjs[ $adjIndex ] . ' ' . $nouns[ $nounIndex ];
}
return $list;
}
Conclusion
Things like this are always interesting to me, how programming languages affect our thoughts.
In Haskell, it’s enough to think mathematically for cases like this, whereas in PHP you have to dig deep into the specifics of the calculation.
I guess that is the beauty of knowing multiple programming paradigms, but you need to be prepared to do a mental shift depending on which environment you work 🙂
