Abstraction is the process of removing details of objects. We step back from concrete objects to consider a number of objects with identical properties. So a concrete object can be looked at as a “superset” of a more abstract object.
A generalization, then, is the formulation of general concepts from specific instances by abstracting common properties. A concrete object can be looked at as a “subset” of a more generalized object.
Per Wikipedia, an algebraic data type is a kind of composite type, i.e., a type formed by combining other types.
Haskell’s algebraic data types are named such since they correspond to an initial algebra in category theory, giving us some laws, some operations and some symbols to manipulate. — Don Stewart
In Mathematics, there are many curves. From a constant curve , to a linear one , to a quadratic one to …, you name it.
Now, imagine that there is a huge data set with some points (think ordered pairs for simplicity), but not all points are defined. Essentially, machine learning is all about coming up with a curve (based on a chosen model) by filling gaps.
Once we agree on the model we want to use (curve we want to represent), we start with some basic equation and then tweak its parameters until it perfectly matches the data set points. This process of tweaking (optimization) is called “learning”. To optimize, we associate a cost function (the error or delta between the values produced by the equation and the data set) and we need to find for which parameters this cost is minimal.
Gradient descent is one algorithm for finding the minimum of a function, and as such it represents the “learning” part in machine learning. I found this video by StatQuest, along with this video by 3Blue1Brown to be super simple explaining these concepts, and naturally, this article will be mostly based on them.
In this article I will assume some basic set theory, and also derivatives. Further, through example, we will:
I’ve almost finished reading Paul Halmos’ Naive Set Theory. The book is highly technical, therefore it may not be suitable for everyone. I wanted to dig deeper into the technicalities, so that’s the main reason I chose to work through it.
I recommend reading Daniel Velleman’s How To Prove It before tackling this one. How To Prove It is a book about mathematical proofs, but it involves proving properties about sets so you learn both proofs and sets on the way.
Here’s a quick summary of my thoughts on the book and set theory in general.
Introduction
What is a set? A set is a collection of objects. That’s all it is! As simple as that sounds, sets are very important in mathematics. This simplicity is what sparked interest for me.
In fact, (almost) all of mathematics is built upon sets! Set Theory is one of the widely accepted foundations of mathematics. There are also some other theories, but we won’t get into that.
Different mathematical ideas usually need an apparatus to be described. Very often this apparatus is Set Theory.
Examples
Example 1: Consider Probability Theory as a branch of mathematics. To represent a sample space of, for example a dice roll, we usually say . So is a set which contains all the possible outcomes. Rolling an even number is represented by some other set, , where but also note that . There’s a relation between and , and this relation is “subset”, as we have observed. Relations needn’t necessarily be always a subset, but we digress a little. What’s the probability to roll an even number, given the sample space? It’s simply . We just used set theory to calculate the probability of rolling an even number of a 6-sided dice!
If you don’t quite understand the notation in the previous paragraph, don’t worry. It’s really simple, and I have already covered it in a previous post, Abstractions with Set Theory.
Example 2: So Probability was one example, but it goes farther than that. Turing Machines (the computation model that your computer/phone/etc uses) can also be described through set theory. Any computation can be represented through sets, which is really awesome.
Example 3: Another interesting example is natural numbers. They can be represented as: , i.e. the empty set, i.e. a set containing the empty set, , well, you get the idea 😀
Example 4: As we noted earlier, there was a relation between two sets, namely the “subset” relation. Relations can be generalized further, and are used to describe some shared property between objects. For example, may be a valid relation on some set, for example, the natural numbers.
Example 5: Abstraction goes further with Algebraic Structures. For example, a Magma represents a set together with some binary operation (it can be anything!). An example, natural numbers with operation plus makes a Magma.
Conclusion
As you can see, there are too many abstractions! What’s the point in generalizing all of this and introducing all these weird names like Magma, etc? Well, it’s similar to what we do with code. Think about how we generalize some calculations in a large software project and we put them in a function with its own name. We don’t care about the details, we only want to look at it and use it from a different abstraction level. This function has its own properties and behavior which can be observed while we code (e.g. it accepts some specific arguments, or returns either an array or int, etc). Same with mathematics!
Recursion Theorem
Meta: As I mentioned, this book is highly technical. Note this is a 100-page book and I spent almost a year on it – on and off. The thing is, you don’t read it like a storybook. Think of it more like a Sudoku puzzles book. When I’m in the mood, I sit down and “solve” some puzzles. Sometimes, even for myself, some of the technical explanations are hard to understand. But I don’t give up – I re-read them a lot of times. When it clicks, I get a very good feeling. Like when you learn a new trick. It’s a very similar feeling to programming. Try to think of some task that you worked on and you learned a new cool trick. It feels good, and you can’t wait to apply this trick again and again until it gets boring. 🙂
So we can conclude that Set Theory is a really powerful apparatus. I hope these examples sparked some interest for you too!
 , to a linear one
, to a linear one 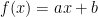 , to a quadratic one
, to a quadratic one  to …, you name it.
to …, you name it. . So
. So  is a set which contains all the possible outcomes. Rolling an even number is represented by some other set,
is a set which contains all the possible outcomes. Rolling an even number is represented by some other set,  , where
, where  but also note that
but also note that  . There’s a relation between
. There’s a relation between  . We just used set theory to calculate the probability of rolling an even number of a 6-sided dice!
. We just used set theory to calculate the probability of rolling an even number of a 6-sided dice! , i.e. the empty set,
, i.e. the empty set,  i.e. a set containing the empty set,
i.e. a set containing the empty set,  , well, you get the idea 😀
, well, you get the idea 😀 may be a valid relation on some set, for example, the natural numbers.
may be a valid relation on some set, for example, the natural numbers.
