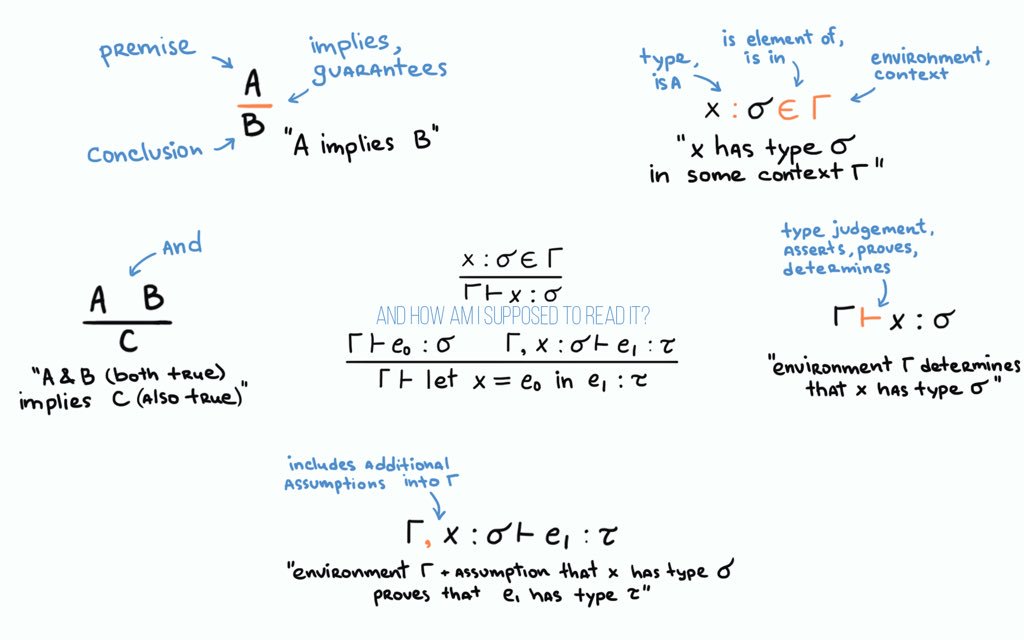
If 1 and 2 don’t make much sense, I found this picture on Twitter to be useful:
For being either or , Calculus of Constructions has the following inference rule:
What this rule means is that can only be of type , if is of type , or is of type .
The questions that I had were:
What are the (dis)advantages of limiting to be ?
Alternatively, what are the (dis)advantages of allowing infinite subtyping (allowing terms to be used as types)?
Why do we have these base types and ?
First of all, we can already “emulate” something like “infinite subtyping” in Coq. For example, to “construct” foo : 3 : Nat : Type we can implement F : nat -> Type, then we have that F 3 : Type. Further, we can implement F' : F 3 -> Type, so F' foo is possible. It’s still of type Type but it kinda works.
But, what happens if we lift this restriction? Well that’s not an easy thing to do. At the very least we need some kind of well-formedness condition in place of , otherwise we can get judgements like . So plainly lifting that restriction not only allows arbitrary terms that are not types, it even allows ill-typed terms which do not type-check.
So foo : 3 : Nat : Type kind of makes no sense. To the left, we have the values we actually compute on; types classify those, and can in turn be classified. In other words, a : b means that a is an element of the “collection” b, but some of these elements are not collections.
So the reason why we have types/values distinction is computation and we can’t really bring them at the “same” level, even though dependent types try to blur the line between the two. We can have values in types, and types in values, but there’s still a difference.
This is why that judgement rule is so important 🙂
As usual, somebody had already considered this 🙂 I started a discussion on #coq@freenode and ##dependent@freenode and got some great answers. Thanks to pgiarrusso, lyxia, and mietek.
I was watching an interesting video, Opening Keynote by Edward Kmett at Lambda World 2018. Note in the beginning of that video how in Haskell you’d put code comments in place of proofs.
Enter Idris.
As a short example, we can abstract a proven Monoid as an interface:
interface ProvenMonoid m where
mappend : m -> m -> m
mempty : m
assocProof : (a, b, c : m) -> mappend a (mappend b c) = mappend (mappend a b) c
idProofL : (a : m) -> mappend mempty a = a
idProofR : (a : m) -> mappend a mempty = a
Do Nats make a Monoid? Sure they do, and here’s the proof for that:
implementation ProvenMonoid Nat where
mappend x y = x + y
mempty = 0
-- Proofs that this monoid is really a monoid.
assocProof = plusAssociative
idProofL = plusZeroLeftNeutral
idProofR = plusZeroRightNeutral
Note that plusAssociative, plusZeroLeftNeutral, and plusZeroRightNeutral are already part of Idris’ prelude. In the next example we’ll do an actual proof ourselves instead of re-using existing proofs.
What about List of Nats? Yep.
implementation ProvenMonoid (List Nat) where
mappend x y = x ++ y
mempty = []
-- Proofs that this monoid is really a monoid.
assocProof [] b c = Refl
assocProof (a::as) b c = rewrite assocProof as b c in Refl
idProofL a = Refl
idProofR [] = Refl
idProofR (x::xs) = rewrite idProofR xs in Refl
Let’s assume that there’s an algorithm running in production that relies on Monoids. What we don’t want to happen is associativity to break, because if it does then the “combine” function applied on all of the produced results will likely be wrong.
🙂
EDIT: Updated first example per u/gallais’s comment.
A binary relation is a partial order if the following properties are satisfied:
Reflexivity, i.e.
Transitivity, i.e.
Antisymmetry, i.e.
Let’s abstract this in Idris as an interface:
interface PartialOrder (a : Type) (Order : a -> a -> Type) | Order where
total proofReflexive : Order n n
total proofTransitive : Order n m -> Order m p -> Order n p
total proofAntisymmetric : Order n m -> Order m n -> n = m
The interface PartialOrder accepts a Type and a relation Order on it. Since the interface has more than two parameters, we specify that Order is a determining parameter (the parameter used to resolve the instance). Each function definition corresponds to the properties above.
This interface is too abstract as it is, so let’s build a concrete implementation for it:
implementation PartialOrder Nat LTE where
proofReflexive {n = Z} = LTEZero
proofReflexive {n = S _} = LTESucc proofReflexive
proofTransitive LTEZero _ = LTEZero
proofTransitive (LTESucc n_lte_m) (LTESucc m_lte_p) = LTESucc (proofTransitive n_lte_m m_lte_p)
proofAntisymmetric LTEZero LTEZero = Refl
proofAntisymmetric (LTESucc n_lte_m) (LTESucc m_lte_n) = let IH = proofAntisymmetric n_lte_m m_lte_n in rewrite IH in Refl
Now you can go and tell your friends that the data type LTE on Nats makes a partial order 🙂
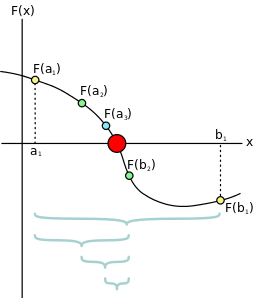
According to Wikipedia, the bisection method in mathematics is a root-finding method that repeatedly bisects an interval and then selects a subinterval in which a root must lie for further processing. We can use this method to find zeroes of some continuous function.
Image used from Wikipedia
Finding zeroes of a function is a very useful concept in practice. Since the function can be almost anything, this means that we can solve about any equality.
For a given continuous function , and an interval , where and (that is, the function changes sign for some value in that interval), the algorithm thus tries to minimize such that , where .
The algorithm is as follows:
Set interval
Calculate
If is sufficiently small, stop
Else if , then set
Else, set
Goto 1
As always, definitions are best understood with examples, so we’ll give a few examples.
Example 1: Approximating square root
We will start by approximating the value of . The function we want to find zero for is then , since . We have that , thus our interval is .
Let's apply the algorithm a few times now:
a
b
2
4
2
3
2
2.5
2
2.25
2.125
2.25
2.1875
2.25
So, 2.21875 is a close approximation of . We can make it even closer by applying the algorithm a couple of more times.
Example 2: Finding a bad commit in a sequence of commits
As a second example, let’s imagine a function that will represent a bunch of Git commits, where one of the commits are bad. Let’s pick such a function at random, maybe . We will also agree that the function returns a value greater than 0 if the software is functioning at that point of commit, and a value less than or equal to 0 otherwise.
How will you find the bad commit? Brute-force or linear search is one way, but it may not be as efficient as bisecting. You can graph the function and look at its zeroes, but that’s a bit cheating, and usually impossible to do in practice with git-bisect since we cannot cover all predicates (in which case here is “software is functioning”), and thus cannot construct a graph of all such functions w.r.t commits. Since we’re cool, we’ll use the bisection method.
Let’s start at random, knowing at least one good and one bad commit. Maybe picking the interval is a good start. We have that .
Our task is to find which commit caused the software to break. Let's apply the same algorithm.
a
b
50
10
50
30
40
30
So, in just 3 steps we found that the bad commit was 35.
Git-bisect
git-bisect is a very useful command. Given a sequence of commits, it allows you to find a commit that satisfies some property.
The way bisect works is that it will find zeroes of the function . So, given an interval of commits , the function will return such that holds for it.
The fastest way to do that is to use bisection, which we explained earlier. Git uses good and bad for bisecting left and right.
For example, let’s assume we have the following setup:
For the sake of this demo, let’s assume the the only acceptable string in a list of strings is “Hello World!”. So the latest commit is now broken. In order to find which commit broke this, we can use bisect as follows:
bor0@boro:~$ git bisect start
bor0@boro:~$ git bisect bad 8d28e4a
bor0@boro:~$ git bisect good faf3b15
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[c9b527bbd44542fb7d69df15ce82919055b36578] Second commit
bor0@boro:~$ cat test.txt
Hello World!
Hello Worldd!
bor0@boro:~$ git bisect bad
c9b527bbd44542fb7d69df15ce82919055b36578 is the first bad commit
commit c9b527bbd44542fb7d69df15ce82919055b36578
Author: Boro Sitnikovski <buritomath@gmail.com>
Date: Sun Oct 21 20:10:44 2018 +0200
Second commit
:100644 100644 980a0d5f19a64b4b30a87d4206aade58726b60e3 0c5b693e0f16f325e967f6482d4f9fe02159472b M test.txt
bor0@boro:~$
It was easy in this case, since we had 3 commits. But if you had 1000 commits, it would only take about 10 good or bad choices, which is cool.
So our property was , and so our function (the result of git bisect) returned c9b527bbd44542fb7d69df15ce82919055b36578, the first commit where the property was satisfied.
As a conclusion, it’s interesting to think that we’re actually finding a zero of a function when we use git-bisect 🙂
Lambda calculus is a formal system for representing computation. As with most formal systems and mathematics, it relies heavily on substitution.
We will start by implementing a subst procedure that accepts an expression e, a source src and a destination dst which will replace all occurences of src with dst in e.
Next, based on this substitution we need to implement a beta-reduce procedure that, for a lambda expression will reduce to , that is, with all within replaced to .
Our procedure will consider 3 cases:
Lambda expression that accepts zero args – in which case we just return the body without any substitutions
Lambda expression that accepts a single argument – in which case we substitute every occurrence of that argument in the body with what’s passed to the expression and return the body
Lambda expression that accepts multiple arguments – in which case we substitute every occurrence of the first argument in the body with what’s passed to the expression and return a new lambda expression
Before implementing the beta reducer, we will implement a predicate lambda-expr? that returns true if the expression is a lambda expression, and false otherwise:
> (beta-reduce '(lambda (n f x) (f (n f x))) '(lambda (f x) x))
'(lambda (f x) (f ((lambda (f x) x) f x)))
It seems that we can further apply beta reductions to simplify that expression. For that, we will implement lambda-eval that will recursively evaluate lambda expressions to simplify them:
> ; Church encoding: 1 = succ 0
> (lambda-eval '((lambda (n f x) (f (n f x))) (lambda (f x) x)))
'(lambda (f x) (f x))
> ; Church encoding: 2 = succ 1
> (lambda-eval '((lambda (n f x) (f (n f x))) (lambda (f x) (f x))))
'(lambda (f x) (f (f x)))
> ; Church encoding: 3 = succ 2
> (lambda-eval '((lambda (n f x) (f (n f x))) (lambda (f x) (f (f x)))))
'(lambda (f x) (f (f (f x))))
There’s our untyped lambda calculus 🙂
There are a couple of improvements that we can do, for example implement define within the system to define variables with values. Another neat addition would be to extend the system with a type checker.
EDIT: As noted by a reddit user, the substitution procedure is not considering free/bound variables. Here’s a gist that implements that as well.
, we can infer that
, which we denote as









 is a partial order if the following properties are satisfied:
is a partial order if the following properties are satisfied:


 , and an interval
, and an interval  , where
, where  and
and  (that is, the function changes sign for some value in that interval), the algorithm thus tries to minimize
(that is, the function changes sign for some value in that interval), the algorithm thus tries to minimize 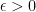 such that
such that  , where
, where  .
.

 , then set
, then set 

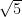 . The function we want to find zero for is then
. The function we want to find zero for is then  , since
, since  . We have that
. We have that  , thus our interval is
, thus our interval is  .
.






 . We can make it even closer by applying the algorithm a couple of more times.
. We can make it even closer by applying the algorithm a couple of more times. . We will also agree that the function returns a value greater than 0 if the software is functioning at that point of commit, and a value less than or equal to 0 otherwise.
. We will also agree that the function returns a value greater than 0 if the software is functioning at that point of commit, and a value less than or equal to 0 otherwise. (in which case
(in which case  is a good start. We have that
is a good start. We have that  .
.


 . So, given an interval of commits
. So, given an interval of commits  , the function will return
, the function will return 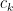 such that
such that  holds for it.
holds for it. , and so our function
, and so our function  (the result of
(the result of  will reduce to
will reduce to ![t[x := s]](https://s0.wp.com/latex.php?latex=t%5Bx+%3A%3D+s%5D&bg=ffffff&fg=000000&s=0&c=20201002) , that is,
, that is,  with all
with all  .
.