For most of my schooling (basic school, high school), I’ve had a private math teacher thanks to my parents. I believe this has shaped my career path for the better.
I’ve always wanted to be a programmer, and I used to be interested in nothing else. Now I am lucky for the past years to be doing exactly what I’ve always wanted, and that is programming.
Back in basic school, I remember one thing that one of my math teachers kept reminding me: “Study math, it is very closely related to programming”. Now I think I really understand what that statement means.
In any case, I’ve recently started digging into Lean Theorem Prover by Microsoft Research. Having some Haskell experience, and experience with mathematical proofs, the tutorial is mostly easy to follow.
I don’t have much experience with type theory, but I do know some stuff about types from playing with Haskell. I’ve heard about the Curry-Howard correspondence a bunch of times, and it kind of made sense, but I haven’t really understood it in depth. So, by following the Lean tutorial, I got to get introduced to it.
An excerpt from Wikipedia:
In programming language theory and proof theory, the Curry–Howard correspondence (also known as the Curry–Howard isomorphism or equivalence, or the proofs-as-programs and propositions- or formulae-as-types interpretation) is the direct relationship between computer programs and mathematical proofs.
In simpler words, a proof is a program, and the formula it proves is the type for the program.
Now as an example, consider your neat function of swapping 2 values of a product type:
swap :: (a, b) -> (b, a) swap (a, b) = (b, a)
What the Curry-Howard correspondence says is that this has an equivalent form of a mathematical proof.
Although it may not be immediately obvious, think about the following proof:
Given P and Q, prove that Q and P.
What you do next is use and-introduction and and-elimination to prove this.
How does this proof relate to the swap code above? To answer that, we can now consider these theorems within Lean:
variables p q : Prop theorem and_comm : p ∧ q → q ∧ p := fun hpq, and.intro (and.elim_right hpq) (and.elim_left hpq) variables a b : Type theorem swap (hab : prod a b) : (prod b a) := prod.mk hab.2 hab.1
Lean is so awesome it has this #check command that can tell us the complete types:
#check and_comm -- and_comm : ∀ (p q : Prop), p ∧ q → q ∧ p #check swap -- swap : Π (a b : Type), a × b → b × a
Now the shapes are apparent.
We now see the following:
and.introis equivalent toprod.mk(making a product)and.elim_leftis equivalent to the first element of the product typeand.elim_rightis equivalent to the second element of the product type- forall is equivalent to the dependent type pi-type
A dependent type is a type whose definition depends on parameters. For example, consider the polymorphic type List a. This type depends on the value of a. So List Int is a well defined type, or List Bool is another example.More formally, if we’re given
A : TypeandB : A -> Type, then B is a set of types over A.
That is, B contains all typesB afor eacha : A.
We denote it asPi a : A, B a.
As a conclusion, it’s interesting how logical AND being commutative is isomorphic to a product type swap function, right? 🙂
 .
. .
. for the base case, which is true (based on definition of add).
for the base case, which is true (based on definition of add). , and try to prove that
, and try to prove that  .
. .
. , which is what we needed to show.
, which is what we needed to show. .
. .
.
 .
.
 , which is the lemma we’ll use in our Coq proof, note we have as givens
, which is the lemma we’ll use in our Coq proof, note we have as givens  (since
(since  ).
).

 for the second case, combined with the first case, we can conclude that
for the second case, combined with the first case, we can conclude that  .
.
 , we use induction on n.
, we use induction on n.
 , which is true.
, which is true. for some
for some  . Note that
. Note that  , so we’re good to multiply with a positive number.
, so we’re good to multiply with a positive number. , which is what we needed to show.
, which is what we needed to show.
 and
and  .
.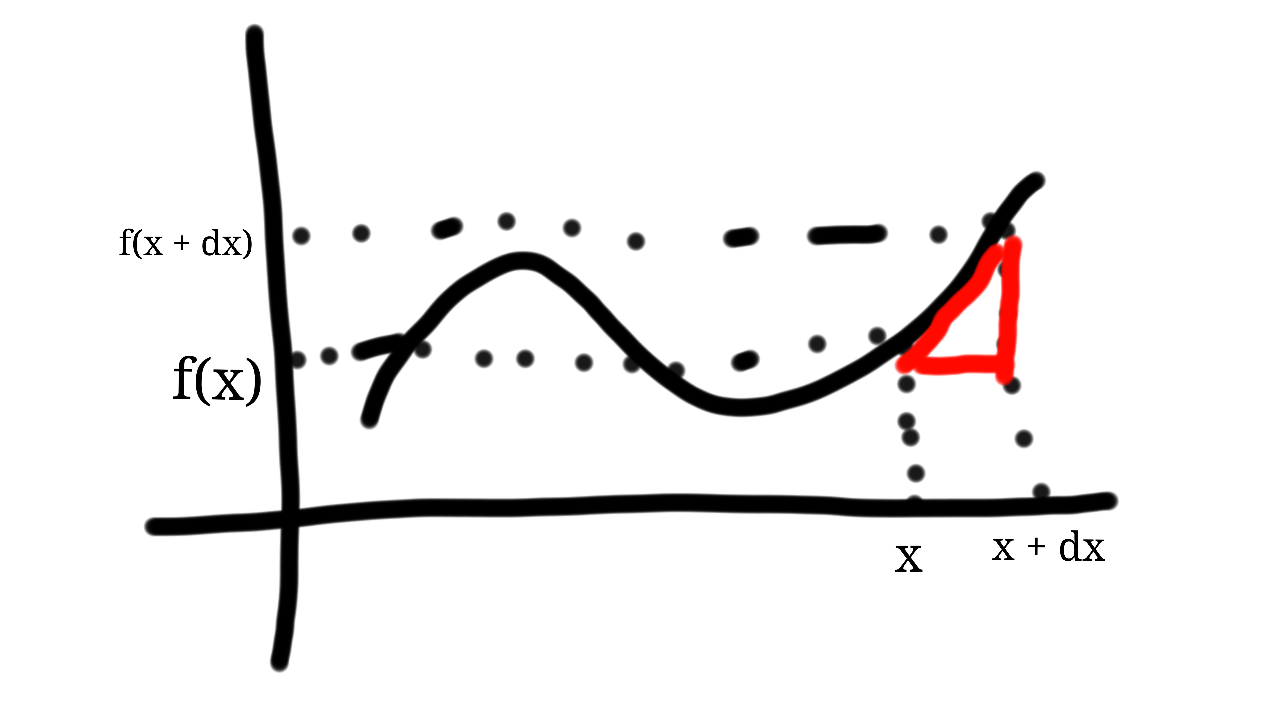
 .
. .
. . So now we have:
. So now we have:  .
. will give us the actual slope (according to the definition of an equation of a line) at x.
will give us the actual slope (according to the definition of an equation of a line) at x. . This slope is actually our definition of a derivative. This definition lies at the heart of calculus.
. This slope is actually our definition of a derivative. This definition lies at the heart of calculus.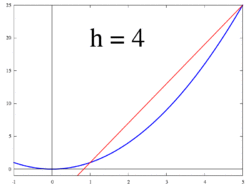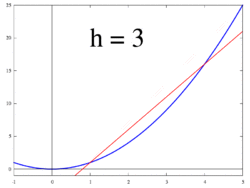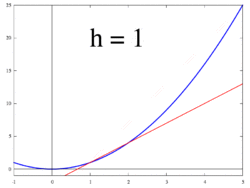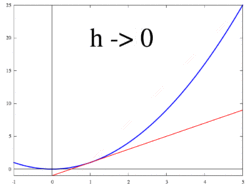
 . This is an approximation rather than an equivalence because we already calculated the limit for one term but not the rest. As dx -> 0, the approximation -> equivalence.
. This is an approximation rather than an equivalence because we already calculated the limit for one term but not the rest. As dx -> 0, the approximation -> equivalence.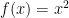 then
then  . So
. So  . That’s an error of just 0.25 for dx = 0.5. Algebra shows for this particular case the error to be dx^2. For dx = 0.1, the error is just 0.01.
. That’s an error of just 0.25 for dx = 0.5. Algebra shows for this particular case the error to be dx^2. For dx = 0.1, the error is just 0.01.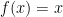 in the interval
in the interval ![[0, 2]](https://s0.wp.com/latex.php?latex=%5B0%2C+2%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Recall that the area of a rectangle with size
. Recall that the area of a rectangle with size 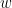 by
by  is
is  . Our approach will be to construct many smaller rectangles and sum their area.
. Our approach will be to construct many smaller rectangles and sum their area.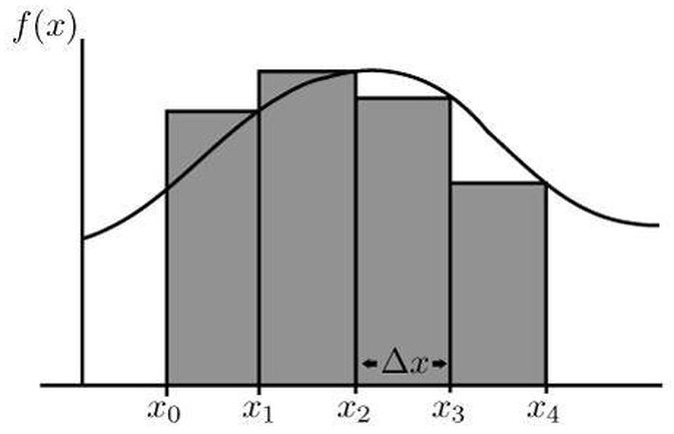
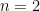 – two rectangles. We have the data points
– two rectangles. We have the data points  , which give us two rectangles with width and height
, which give us two rectangles with width and height  and
and  respectively – note the width is constant because the spaced interval is distributed evenly. To sum the area of this spaced interval, we just sum
respectively – note the width is constant because the spaced interval is distributed evenly. To sum the area of this spaced interval, we just sum  . But note that there’s an error, since the rectangles do not cover the whole area. The main idea is the more rectangles, the less the error and the closer we get to the actual value.
. But note that there’s an error, since the rectangles do not cover the whole area. The main idea is the more rectangles, the less the error and the closer we get to the actual value.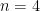 . We have the data points
. We have the data points  . Since we have four elements, in the range
. Since we have four elements, in the range  . The result is
. The result is ![0.5 [ f(0.5) + f(1) + f(1.5) + f(2) ] = 2.5](https://s0.wp.com/latex.php?latex=0.5+%5B+f%280.5%29+%2B+f%281%29+%2B+f%281.5%29+%2B+f%282%29+%5D+%3D+2.5&bg=ffffff&fg=000000&s=0&c=20201002) .
. – when
– when 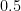 . Generalizing for
. Generalizing for  , the difference between
, the difference between  and
and  will be
will be  . Also, generalizing the summation gives
. Also, generalizing the summation gives  , and since we only consider evenly spaced intervals we have
, and since we only consider evenly spaced intervals we have  , for all
, for all  . This is called a Riemann sum and defines the integral
. This is called a Riemann sum and defines the integral  , where
, where  . Also, since
. Also, since  is the starting point, that gives
is the starting point, that gives  .
. . From here, we evaluate the inner sum
. From here, we evaluate the inner sum  . Plugging back in gives
. Plugging back in gives  .
.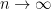 . Note that
. Note that  so we have
so we have  , which finally gives
, which finally gives  . This represents the sum of the area
. This represents the sum of the area ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002) under the curve of the function
under the curve of the function 