Like in programming, building abstractions in mathematics is of equal importance.
However, the best way to understand something is to get to the bottom of it. Start by working on the foundations level upwards.
So we will start with the most basic object (the unordered collection) and work our way up to defining functions.
Set
A set is an unordered collection of objects. This might sound too abstract but that’s what it is. The objects can be anything. It is usually denoted by comma separating the list of objects and enclosing them using curly braces.
For example, one set of fruits is  .
.
Since it is an unordered collection we have that  .
.
For membership, we denote  to say that apple is in that collection.
to say that apple is in that collection.
Tuples
An n-tuple is an ordered collection of n objects. As with sets, the objects can be anything. It is usually denoted by comma separating the list of objects and enclosing them using parenthesis.
We can represent it using unordered collections as follows: Consider the tuple  . We can use the set
. We can use the set  . Note that here I’m using natural numbers and I assume them to be unique atoms. Otherwise, if we represented naturals in terms of set theory, there would be issues with this definition. For that, we’d have to use Kuratowski’s definition, but we can skip that for simplicity’s sake.
. Note that here I’m using natural numbers and I assume them to be unique atoms. Otherwise, if we represented naturals in terms of set theory, there would be issues with this definition. For that, we’d have to use Kuratowski’s definition, but we can skip that for simplicity’s sake.
Now to extract the k-th element of the tuple, we can pick x s.t.  .
.
So now we have that  , that is two tuples are equal iff their first and second elements respectively are equal. This is what makes tuples ordered.
, that is two tuples are equal iff their first and second elements respectively are equal. This is what makes tuples ordered.
One example of a tuple is  which represents 3 hours of a day sequentially.
which represents 3 hours of a day sequentially.
Relations
An n-ary relation is just a set of n-tuples with different values. We are mostly interested in binary relations.
One example of such a relation is the “is bigger than”. So we have the following set:  .
.
Functions
Now we can define functions in terms of relations.
To do that we first have to discuss subset. A is a subset of B if all elements of A are found in B (but not necessarily vice-versa). We denote it as such:  . So for example:
. So for example:  and
and  . But this doesn’t hold:
. But this doesn’t hold:  .
.
So with this, a function is a mapping from a set A to a set B, or in other words it is a subset of all combinations of ordered pairs whose first element is an element of A and second element is an element of B.
For example, if  then the combinations are:
then the combinations are:  . A function f from A to B is denoted
. A function f from A to B is denoted  and is a subset of F:
and is a subset of F:  .
.
This combination of pairs is called a Cartessian product, and is defined as the set:  .
.
We have one more constraint to add to a function, namely that it cannot produce 2 or more different values for a single input. So using either of f(a) = 1 or f(a) = 2 or f(a) = 3 is okay, but not all three of them. That means that we only have to use one of  from our example set above. The same reasoning goes for b. So
from our example set above. The same reasoning goes for b. So  with
with  is one valid example.
is one valid example.
We can also express recurrent relations like  for
for  .
.
Conclusion
Matrices (tuples of tuples), lists (sets or tuples), graphs* (set of sets), digraphs (set of tuples), trees (graphs) can also be derived similarly.
This is what makes the set a powerful and interesting idea.
*:  with vertices
with vertices  and edges
and edges 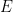 . E.g.:
. E.g.: 










 , this line passes through the point
, this line passes through the point  .
. .
.


 .
. as our goal. If we click Start, we see that it proves it immediately.
as our goal. If we click Start, we see that it proves it immediately.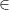 denotes set membership, and that’s it. Because that’s all there’s to it, it’s like an atom. So let’s say that member(x, y) denotes that.
denotes set membership, and that’s it. Because that’s all there’s to it, it’s like an atom. So let’s say that member(x, y) denotes that.