I was looking at Wikipedia’s article regarding Monoids, and decided that it was interesting to make a post regarding the section “Monoids in Computer Science” http://en.wikipedia.org/wiki/Monoid#Monoids_in_computer_science.
So there they have posted this formula: 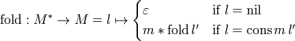
And let’s also take a look at Haskell’s definition for fold:
(>>>) = (++)
fold [] = []
fold (m:l') = m >>> (fold l')
Notice the relation between the formulas? Just replace >>> with *, and there you have it!
Regarding the types, in Haskell we have:
*Main> :t fold
fold :: [[a]] -> [a]
And in Mathematics, we have:
fold: M* -> M
The star here represents Kleene’s star, and it is defined to be all concatenations on the elements of the set M, including the empty string (). Example, if M = {a, b} then M* = {(), (a), (b), (a,a), (a,b), (b,b), (b,a), (a,b,a), …}. So what this means is, that if we have M defined as list of integers, then M* would be list of list of integers (which is the result of list concatenation of the elements of M).
And what is fold? Well, fold basically takes a Monoid and applies its operation. Now that we have these two formulas, we can show how fold operates on a Monoid.
Let’s consider the Monoid M ([Int], ++, []). First, to prove that this triple makes a monoid, we must first take a look at the definition of ++:
[] ++ ys = ys
(x:xs) ++ ys = x : (xs ++ ys) (*)
1. Closure
Namely, the (++) is the list concatenation operator, and when we concatenate two lists, we get list as an output, according to ++ definition.
2. Associativity
(xs ++ ys) ++ zs = xs ++ (ys ++ zs), order of evaluation will not change the resulting list
To prove this, we again need to look at ++ definition.
We can use Structural Induction in order to prove associativity.
Base case: If we let x = ys + zs, then [] ++ x = x by definition, LHS equals to x. and for the RHS, we get “” + ys = ys by definition, so ys ++ zs == x, and so LHS = RHS.
Inductive step: Assume that (xs ++ ys) ++ zs = xs ++ (ys ++ zs)
We need to prove that ((x:xs) ++ ys) ++ zs = (x:xs) ++ (ys ++ zs)
LHS: by (*) = (x : (xs ++ ys)) ++ zs => let xs ++ ys = p => x : p ++ zs = x : ((xs ++ ys) ++ zs)
RHS: by (*) = x : (xs ++ (ys ++ zs)) => by assumption => x : ((xs ++ ys) ++ zs)
So we get that LHS = RHS.
3. Identity
The empty list [] is the identity here, because [] ++ ys or ys ++ [] always equals to ys, according to ++ definition (already proved by base case in 2).
Now, we can start playing around with our fold:
*Main> fold [[1,2], [3]] -- per Monoid M
[1,2,3]
*Main> fold [['a'],['b'],['c']] -- same as Monoid M, but operates on set [Char] instead of [Int]
"abc"
