In Mathematics, there are many curves. From a constant curve  , to a linear one
, to a linear one 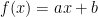 , to a quadratic one
, to a quadratic one  to …, you name it.
to …, you name it.
Now, imagine that there is a huge data set with some points (think ordered pairs for simplicity), but not all points are defined. Essentially, machine learning is all about coming up with a curve (based on a chosen model) by filling gaps.
Once we agree on the model we want to use (curve we want to represent), we start with some basic equation and then tweak its parameters until it perfectly matches the data set points. This process of tweaking (optimization) is called “learning”. To optimize, we associate a cost function (the error or delta between the values produced by the equation and the data set) and we need to find for which parameters this cost is minimal.
Gradient descent is one algorithm for finding the minimum of a function, and as such it represents the “learning” part in machine learning. I found this video by StatQuest, along with this video by 3Blue1Brown to be super simple explaining these concepts, and naturally, this article will be mostly based on them.
In this article I will assume some basic set theory, and also derivatives. Further, through example, we will:
- Define what the curve (model) should be
- Come up with a data set
- Do the “learning” using gradient descent
Continue reading “Brief introduction to Machine Learning with Gradient Descent” →